The first CLAUDE.md I ever wrote was for a single-package Astro site. It was maybe forty lines. Half of it was “here is the stack, here is how you deploy it,” and the other half was a handful of rules I’d caught myself repeating in chat. It worked. Every new Claude Code session started off oriented in roughly the right direction, and I stopped explaining the deploy script for the fiftieth time.
Then I started working in a monorepo — one repo, four packages, each with its own stack and its own conventions — and the same approach fell over. The root CLAUDE.md grew to 300 lines. Then 500. I was pasting the Postgres schema into it. I was listing every npm script. I was documenting conventions that only applied to one of the four packages, which meant every session on every package was loading instructions that didn’t apply.
The problem has a shape, and the shape has a fix. This post is about where CLAUDE.md files should live in a monorepo, what goes in each one, and why the naive approach (“everything in the root”) is the most expensive wrong answer you can pick.
The problem: one root, many packages, one context window
A monorepo violates an assumption that a single-package CLAUDE.md quietly depends on: that “this repo” and “this project” are the same thing. In a monorepo they are not. The repo is the unit of version control. The package is the unit of work. When I’m editing packages/db/, I care about Postgres, Drizzle, migration scripts, and seed data. When I’m editing apps/web/, I care about Astro, Tailwind, and the deploy pipeline. These are different briefings. Putting them in the same file means every session gets both.
That costs tokens. Every CLAUDE.md that loads into context takes real input tokens on every tool call, every re-prompt, every compaction boundary. A 3000-token root CLAUDE.md is 3000 tokens of overhead on a session that’s going to make a few hundred tool calls. Multiply across four or five sessions a day across a team, and the waste adds up — not catastrophically, but measurably, and in exchange for worse answers, because most of those tokens are context pollution for the task at hand.
The fix isn’t to shrink the root until it’s useless. It’s to put context at the scope where it’s actually true, and to rely on the fact that Claude Code loads CLAUDE.md files in a hierarchy.
The load order
As of September 2025, Claude Code loads CLAUDE.md from three places, in this order:
- Global —
~/.claude/CLAUDE.md. Your personal defaults. Loaded on every Claude Code session on this machine, regardless of project. - Project root —
<repo>/CLAUDE.md. Loaded when Claude Code detects it’s inside a project with a CLAUDE.md at the repo root. - Nested files on the path from repo root to cwd — if you
cd packages/api-server/and runclaudethere, andpackages/api-server/CLAUDE.mdexists, it loads too. So doespackages/CLAUDE.mdif that exists. Each level on the path from the repo root to your current working directory contributes its CLAUDE.md, if present.
What does not load: sibling CLAUDE.md files. If you’re in packages/api-server/, the CLAUDE.md in packages/db/ does not load. That’s the entire point. The system is designed to scope context to the chain of directories that contains your work.
This is the behavior that makes a layered approach possible. Each file is additive along the path. Global applies everywhere. Root applies to every package. Package-level applies only to that package’s sessions. You don’t pay for the db package’s context when you’re working in the web app.
The four-layer mental model
Here is how I think about where a given piece of context belongs. Four layers, in order of scope:
| Layer | File | Scope |
|---|---|---|
| Global | ~/.claude/CLAUDE.md | Every Claude Code session on my machine, across all projects |
| Project | <repo>/CLAUDE.md | Every session inside this repo |
| Package | <repo>/packages/<name>/CLAUDE.md | Sessions whose cwd is inside this package |
| Task | (no file — the prompt itself) | This specific thing I’m asking right now |
A piece of context belongs at the narrowest layer where it’s actually true. “Use two-space indent” is global — it’s a personal preference. “This repo uses Turborepo and deploys via GitHub Actions” is project. “This package talks to Stripe and the webhook handler lives at src/webhooks/stripe.ts” is package. “Refactor this one file to use the new session helper” is task.
People get this wrong in predictable ways. They put personal preferences in the project CLAUDE.md (now everyone on the team inherits my comment style). They put package-specific conventions in the root (every session on every package drags them along). They write task-level instructions into CLAUDE.md in an attempt to be helpful (“when adding a migration, always run the seed script after”) when the instruction is really a one-time thing for this week’s feature.
The question to ask for every line: would I want this loaded for every session at this scope? If not, demote it one layer. If the answer is still no, it’s task-level — it belongs in your prompt, not a file.
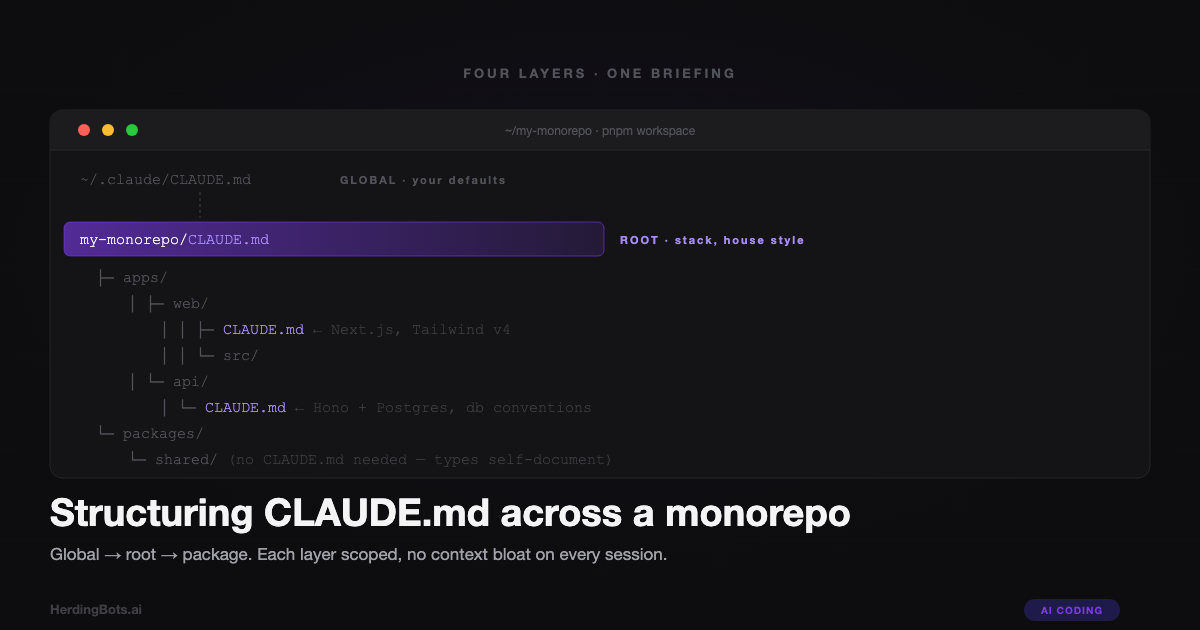
A concrete layout
Here’s what a realistic monorepo CLAUDE.md layout looks like. This is a pnpm-workspaces or Turborepo-style tree, which is roughly the shape of every monorepo I’ve worked in for the past two years.
my-monorepo/
├── CLAUDE.md # project-level: stack, workspace layout, deploy
├── apps/
│ ├── web/
│ │ ├── CLAUDE.md # package-level: Astro, Tailwind, content model
│ │ └── src/
│ └── api/
│ ├── CLAUDE.md # package-level: Fastify, auth, Stripe webhooks
│ └── src/
├── packages/
│ ├── shared/ # no CLAUDE.md — small, self-documenting
│ │ └── src/
│ └── db/
│ ├── CLAUDE.md # package-level: Postgres, Drizzle, migrations
│ └── src/
├── package.json
├── pnpm-workspace.yaml
└── turbo.jsonGlobal lives at ~/.claude/CLAUDE.md and is not in this tree. It applies across every project, so it doesn’t belong to any one of them.
Note packages/shared/ has no CLAUDE.md. That’s deliberate. A package gets a CLAUDE.md when there’s real context that only applies to it and that Claude couldn’t discover quickly from the file layout and package.json. A small utility package with a clear types file and a readable index.ts doesn’t need one. Don’t add CLAUDE.md files reflexively.
What goes at each level
Here’s the same idea as a table. The anti-pattern column is the one that’s cost me the most time.
| Scope | Example content | Example anti-pattern |
|---|---|---|
| Global | ”My name is Dan.” “Don’t write code comments unless asked.” “Never run rm -rf without confirming." | "This project uses Astro.” — project-specific leaking into global. |
| Project root | ”Monorepo uses pnpm workspaces + Turborepo.” “Shared types live in packages/shared.” “Deploy via ./deploy.sh — static output, no server runtime.” | Copying the db package’s schema in verbatim. Now every session everywhere carries 500 tokens of irrelevant SQL. |
| Package | ”This package is the Stripe integration. Webhooks at src/webhooks/stripe.ts use raw body signatures — don’t parse JSON before verifying." | "Always write tests in Jest.” — that’s true of the whole repo, demote to project root. |
| Task prompt | ”Refactor createSession to use the new db.session helper.” | Adding this to a CLAUDE.md “so Claude remembers” — it’s a one-off, not a standing rule. |
The anti-patterns all have the same shape: context at the wrong scope. Either too narrow (task stuff frozen into a file) or too broad (package stuff hoisted into the root). Both leak tokens and introduce drift.
Token budget math
It’s worth working through the numbers, because they’re surprisingly unfriendly.
Say you have:
- Root CLAUDE.md: ~2000 tokens
- Package CLAUDE.md: ~800 tokens
A single Claude Code session starts with ~2800 tokens of memory overhead on top of the system prompt and tool schemas. That’s not catastrophic. But that overhead is re-sent on most tool calls within the session (Claude Code sends conversation history + system context for every turn), and it compounds over long sessions and across sessions.
More important than the raw per-session cost is the cross-scope cost. If the root CLAUDE.md has 1000 tokens of content that’s really package-specific (say, the db package’s schema), then every session on the web app and every session on the API is paying for context that does nothing for it. Across a day of ten sessions, that’s 10,000 tokens of pure waste. Across a team of five developers, it’s 50,000 tokens a day. Again: not ruinous. But zero benefit, and the more packages you have, the worse the leverage.
The math gets strictly worse the larger the root file grows, because you’re paying the same tokens on every unrelated session. The math gets better when content moves to the narrowest scope where it’s true, because then only the relevant sessions pay for it.
The practical implication is not “cut every CLAUDE.md to the bone.” It’s “don’t put something in a broader scope than it actually applies to.” Keep the root trim. Let the packages carry their own weight.
Reference, don’t inline
This is the single rule that keeps CLAUDE.md files small without making them useless: if a piece of context already exists in the code, point to it rather than copying it.
Bad:
## Database schema
The users table has the following columns:
- id: uuid, primary key
- email: text, not null, unique
- created_at: timestamptz, default now()
- ...twenty more lines...Good:
## Database
See `packages/db/schema.ts` for the canonical Drizzle schema.
Migrations live in `packages/db/migrations/` and run via `pnpm db:migrate`.Claude Code reads files on demand. If the current task touches the schema, it will read schema.ts. It does not need the schema pre-loaded into context “just in case.” That’s what tool calls are for. The only reason to inline a piece of context into CLAUDE.md is if it isn’t discoverable from the code itself — unwritten conventions, decisions made in a design doc, things that aren’t in any file.
The test: if a competent developer opening the repo for the first time would find this information in ten seconds of looking at the directory structure and a key file, it doesn’t belong in CLAUDE.md. Just point at the file.
This rule is how you keep a root CLAUDE.md under 2000 tokens for a repo that has real complexity. Most of the complexity is in the code. The CLAUDE.md is a briefing on the parts of the code that aren’t obvious.
Drift and how to fight it
CLAUDE.md files rot. They rot because they’re written once when a convention is fresh, and the convention drifts, and nobody remembers the file exists to update it. Two months later the CLAUDE.md says “we use Zod for validation” and the code has half-migrated to Valibot and nobody’s telling Claude.
The pattern that works for me: every time Claude makes a mistake that a correct CLAUDE.md would have prevented, I update CLAUDE.md. Not “fix the code and move on.” Update the briefing. If I had to correct Claude on which test runner to use, that’s a signal the CLAUDE.md at that scope is missing information. One of three things is true:
- It’s not documented anywhere and needs to be added.
- It is documented but at the wrong scope (the rule was in the root but it only applies to this package, so Claude didn’t weight it correctly).
- It was documented correctly and Claude ignored it, in which case the writing needs to be sharper — shorter, more declarative, less buried.
All three are fixable. None of them get fixed if you treat CLAUDE.md as write-once. I keep an open tab on CLAUDE.md the same way I’d keep an open tab on a test file: it lives alongside the work.
There’s a related failure mode: over-updating. Every mistake becomes a new rule, the CLAUDE.md grows to 800 lines, and Claude starts ignoring it because the signal-to-noise ratio collapsed. The question to ask before adding a rule is: would this rule have prevented this class of mistake, or just this specific mistake? Class-level rules earn a spot in CLAUDE.md. Instance-level corrections belong in the prompt for that task, not as a permanent addition.
Nested-repo edge cases
A few corners of the load-order behavior that are worth knowing.
Git submodules. If your monorepo includes a submodule at, say, vendor/third-party-lib/, the submodule’s own CLAUDE.md — if it has one — loads when you cd into it. This is usually what you want. The submodule is a different project with its own conventions, and you should respect them when working in it. If you don’t want its CLAUDE.md loading, delete or rename it locally; Claude Code is looking for the literal filename.
Nested npm or pnpm workspaces. These are the common case in monorepos and the load order handles them naturally. packages/foo/CLAUDE.md loads when cwd is inside packages/foo/, regardless of where npm considers the workspace boundary. Claude Code uses the filesystem, not package.json, to decide what applies.
Clone-within-clone. Occasionally I’ll have a checkout of another repo inside my current one (maybe for quick cross-reference, or because I’ve symlinked something for local development). The inner repo’s CLAUDE.md will load if you cd into the inner repo. This is fine in theory and surprising in practice — if you’ve forgotten the inner repo is there, you may get briefing notes from a different project. Worth knowing.
The filesystem is the boundary. Claude Code does not walk up past the repo root it started in. If you start it from /Users/me/projects/monorepo/ and cd somewhere outside, it doesn’t follow. Load order is always “what’s in scope of the current cwd, stopping at the project root Claude Code thinks it’s in.”
A minimal example
Here’s a skeletal root CLAUDE.md for the imaginary monorepo above. About 40 lines, which is a good target for a non-trivial multi-package repo.
# Monorepo project guide
## What this is
A pnpm workspace with two apps and two shared packages.
Deploy is static web + a small Node API. No platform lock-in.
## Stack
| Layer | Choice |
|---|---|
| Workspaces | pnpm + Turborepo |
| Web app | Astro (static) |
| API | Fastify on Node 20 |
| DB | Postgres via Drizzle |
| Shared | TypeScript types in `packages/shared` |
## Layout
- `apps/web/` — marketing + dashboard (Astro)
- `apps/api/` — REST API (Fastify)
- `packages/shared/` — types used by both apps
- `packages/db/` — schema, migrations, seed
Each `apps/*` and each non-trivial `packages/*` has its own CLAUDE.md
with stack-specific details. Read the package-level file before editing.
## Commands
- `pnpm dev` — run everything
- `pnpm build` — build everything
- `pnpm test` — Vitest across all packages
- `pnpm --filter <pkg> <cmd>` — package-scoped command
## Conventions
- TypeScript strict everywhere.
- ESM only. No CommonJS.
- Prettier config in root, respected by all packages.
- Never add a root-level dependency; scope to the package that uses it.And a corresponding package-level CLAUDE.md for apps/api/. About 25 lines.
# API package
## What this is
The REST API. Node 20, Fastify, JWT auth, Postgres via Drizzle.
Runs in production as a single process behind a reverse proxy.
## Important files
- `src/server.ts` — Fastify bootstrap
- `src/auth/` — JWT issue + verify
- `src/webhooks/stripe.ts` — uses raw body; do not JSON-parse
before verifying the signature
- `src/routes/` — one file per resource
## DB access
Import the client from `@repo/db`. Don't instantiate Drizzle here.
Migrations are owned by `packages/db/`; run them from there.
## Tests
Vitest, `pnpm --filter api test`.
Integration tests spin up Postgres via testcontainers.Neither file tries to be exhaustive. Both rely on the reader — Claude or a human — following a pointer into the code when they need detail.
What I regret
Two honest anti-patterns I’ve personally shipped and had to walk back.
I kept every npm script in the root CLAUDE.md. Every pnpm build:foo, every pnpm seed:dev, every one-off script that had accumulated over a year. About 3000 tokens of bash incantation. Every session on every package loaded the whole list. The correct home for most of those scripts is the package-level CLAUDE.md, or — better — just package.json, which Claude will cat on its own when it needs to. Moved it out. The root file lost a third of its size and lost nothing in quality.
I pasted the Postgres schema into the root CLAUDE.md. Rationale at the time: “the schema is critical, everyone should have it loaded.” In practice: only the db package and the API touch the schema directly. The web app reads summarized types from packages/shared. So every web-app session was paying for ~500 tokens of SQL it never used, and the schema in the CLAUDE.md gradually diverged from the real one in schema.ts because I was editing the code and not the briefing. Classic drift. Now the root CLAUDE.md has one line — “See packages/db/schema.ts for the canonical schema” — and the authoritative source is the file that’s actually deployed.
Both mistakes were me trying to be helpful by pre-loading context. Both costs were invisible to me until I actually counted tokens and noticed sessions were slow to start. Reference, don’t inline. The code is already there; let Claude read it.
Closing
CLAUDE.md is not documentation. It’s a briefing.
Documentation is for humans who haven’t seen the code before, and its job is to be comprehensive. A briefing is for someone who is about to act, and its job is to be minimal and correct. Every line of CLAUDE.md is consuming context budget that could be spent on the actual task. Every line that’s at the wrong scope is a small tax on every unrelated session. Every line that’s inlined when it could be referenced is a drift liability waiting to happen.
Keep it tight. Keep it scoped. Keep it honest about what’s actually invariant versus what you just happen to believe this week. Let the code carry the details that the code already knows. Let the briefing carry the things the code can’t tell you.
If you want to see this pattern applied to a different file — VS Code workspace settings, which have a surprisingly similar layered model and the same failure modes — I wrote about it in VS Code settings: the local.json hierarchy. The mental model carries over almost directly.